Kernelize Platform
An inference platform that works across chips
Compare inference performance between different chips using the same software stack
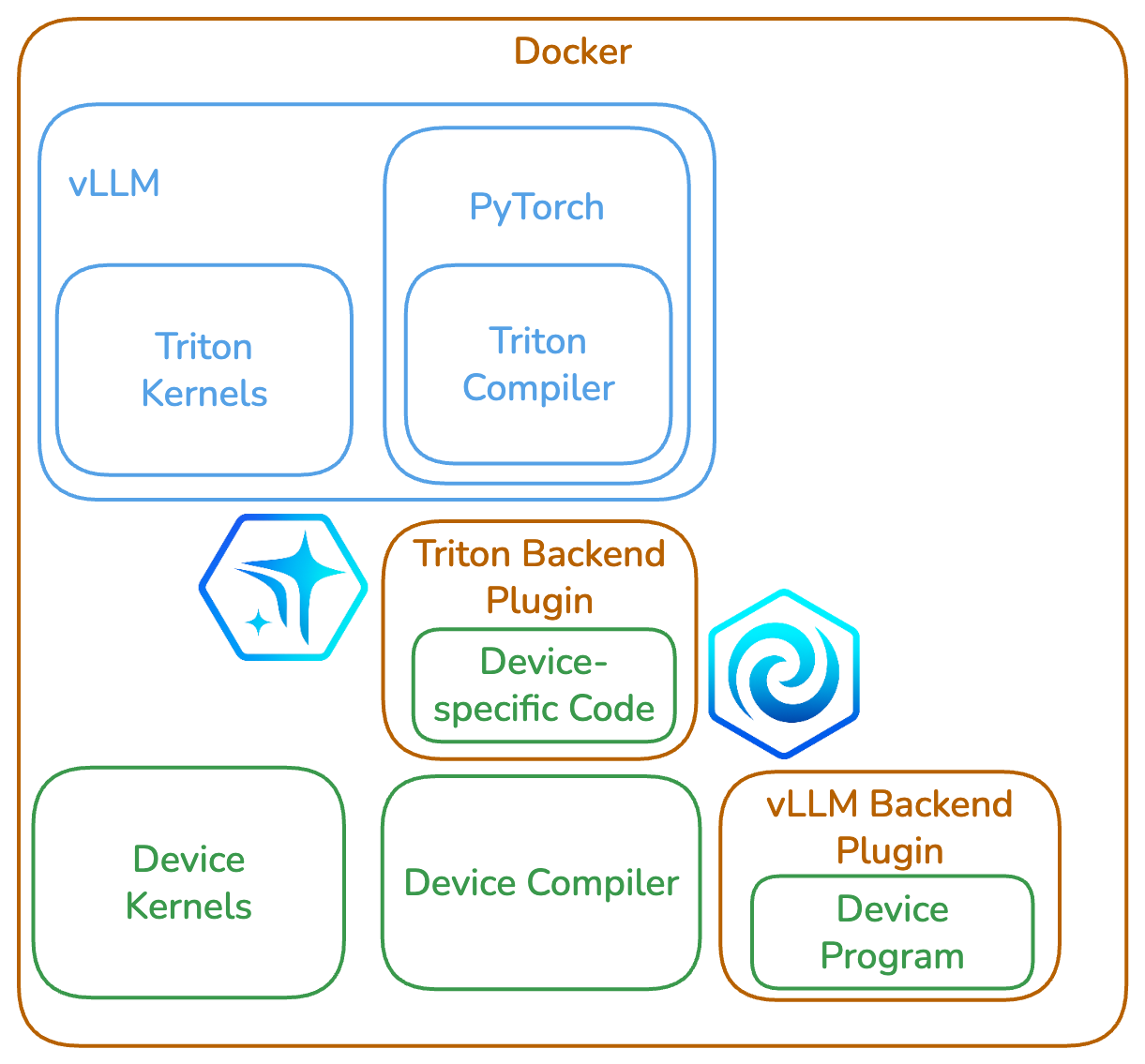
Consistent across chips
Run a consistent inference platform across chips by keeping the core software the same and swapping only chip-specific plugins.
Inference, not benchmarks
Evaluate inference performance by running full models and production workloads instead of isolated benchmarks.
Works with your software
Integrate with your existing ML stack using official Triton backend plugins tested by Kernelize and certified to work in PyTorch and vLLM.
Apples to apples comparisons
- Identical execution semantics across runs
- Same reports for latency, throughput, and memory behavior
- Helps evaluate cost-performance tradeoffs
Evaluate new hardware faster
- Reuse existing models and workflows
- Avoid vendor-specific runtimes and rewrites
- Shorten evaluation and decision cycles
Keep your existing workflows
- Uses official PyTorch and vLLM plugins
- Standard model formats
- No custom kernel languages required
No vendor lock-in
- Built on open-source Triton plugins
- Consistent behavior
- Clean separation between platform and hardware